Tatsuki Ogino
(ogino@stelab.nagoya-u.ac.jp)
Solar-Terrestrial Environment Laboratory, Nagoya University
3-13 Honohara, Toyokawa, Aichi 442-8507, Japan
Abstract:
We have translated a 3-dimensional magnetohydrodynamic (MHD) simulation code of the Earth's magnetosphere from VPP Fortran to HPF/JA on the Fujitsu VPP5000/56 vector-parallel supercomputer and the MHD code was fully vectorized and fully parallelized in VPP Fortran. The entire performance and capability of the HPF MHD code could be shown to be almost comparable to that of VPP Fortran. A 3-dimensional global MHDsimulation of the earth's magnetosphere was performed at a speed of over 400 Gflops with an efficiency of 76.5% using 56 PEs of Fujitsu VPP5000/56 in vector and parallel computation that permitted comparison with catalog values. We have concluded that fluid and MHD codes that are fully vectorized and fully parallelized in VPP Fortran can be translated with relative ease to HPF/JA, and a code in HPF/JA may be expected to perform comparably to the same code written in VPP Fortran.
1. Introduction
We have been able to execute a 3-dimensional global magnetohydrodynamic (MHD) simulation of the interaction between the solar wind and the earth's magnetosphere in order to study the structure and dynamics of the magnetosphere using a variety of computers to run a fully vectorized MHD code [1]-[5]. Among the computers we have used are: CRAY Y-MP, Fujitsu VP-2600, Hitachi S820, and NEC SX-3. This flexibility of using many different computers allowed us to work together with many scientists in performing our computer simulations. However, as vector parallel and massively parallel supercomputers have come into the simulation community, a number of different approaches are now being used [6]-[8]. Many scientists carrying out simulations haveÅ@lost their common language and are being forced to work with new dialects.
We began to use the vector parallel supercomputer, Fujitsu VPP500, in the Computer Center of Nagoya University 1995 and have succeeded in rewriting our 3-dimensional global MHD simulation code in VPP Fortran allowing us to achieve a high performance of over 17 Gflops [8],[9]. Moreover, we have used a new supercomputer, the Fujitsu VPP5000/56, since December 1999 to achieve an even higher performance of over 400 Gflops in VPP Fortran [8],[9],[10]. However, the MHD code in VPP Fortran cannot achieve such a high performance using other supercomputers such as Hitachi SR8000 and NEC SX-5. Thus we face a difficult problem in collaborating in with other scientists in computer simulations even at universities within Japan. We very much hope to recover the advantage of having a common language in the supercomputer world. Recent candidates for this common language appear to be High Performance Fortran (HPF) and Message Passing Interface (MPI). We look forward to the time when we can use these compilers in supercomputers.
In 1999 it was learned that some engineers in Japanese supercomputer companies had tried to develop an extended version of HPF created by the Japanese HPF Association (JAHPF) [11] for use in the new HPF compiler in the near future. This information was of great interest because the performance of the original HPF was questionable and we want to test its performance independently. Since June 2000, we have had the opportunity to use HPF/JA (an extended version of HPF) with a supercomputer of the vector-parallel type, Fujitsu VPP5000/56 [11],[12] and began to translate our 3-dimensional MHD simulation code for the Earth's magnetosphere from VPP Fortran to HPF/JA [4],[9],[12]. The MHD code was fully vectorized and fully parallelized in VPP Fortran [6],[8]. We successfully rewrote the code from VPP Fortran to HPF/JA in three weeks, and an additional two weeks were required to perform a final verification of the results of the calculations. The entire performance and capability of the HPF MHD code are shown to be almost comparable to those of the VPP Fortran code in typical simulations using the Fujitsu VPP5000/56 system.
2. From VPP Fortran to HPF/JA
We requested the Computer Center of Nagoya University to begin using HPFÅ@in their supercomputer as soon as possible. In June 2000, stimulated by a lecture on HPF by a Fujitsu engineer, we began to use HPF/JA on the Fujitsu VPP5000 [11],[12]. We understood that the use of HPF was not very successful in the USA and Europe, and that users would rather abandon the usage of HPF due to its difficulty in achieving a high performance. However, we have high expectations of HPF/JA because supercomputer companies in Japan have had valuable experiences with compilers in operating vector-parallel machines [8],[9]. We haveÅ@decided to translate our MHD code from VPP Fortran to HPF if we can reach 50%Å@of the performance of VPP Fortran using HPF. We have experience in fully vectorizing and parallelizing several test programs and 3-dimensional global MHD codes for the earth's magnetosphere using VPP Fortran. Based on that experience, we believe that we can obtain good performance by translating the MHD codes from VPP Fortran to HPF/JA. The main points of our approach are summarized as follows,
(1) We can use the same domain decomposition (z-direction in 3-dimension) as in VPP
Fortran, and overlap data at the boundary of distributed data which were handled by "sleeve" in VPP Fortran can be replaced by "shadow" and "reflect" in HPF/JA.
(2) Parallelizing formalisms for decomposition are performed by "independent" sentence as is done in VPP Fortran.
(3) Lump transmission of distributed data is done by "asynchronous" sentence.
(4) "Asynchronous" sentence can be used for lump transmission between the distributed data with different directions of decomposition.
(5) Unnecessary communication, which was a problem in HPF, can be removed by the instructions of "independent new ( )" and "on home local ( )".
(6) Maximum and minimum can be calculated in parallel by "reduction".
Fortran programs using VPP Fortran can be directly rewritten using HPF/JA owing to (1)-(3) keeping their original styles. If unnecessary communication could be completely stopped by (5), the efficiency of parallelization could be greatly improved. We can use the instructions to stop unnecessary communication if the calculation results don't change with insertion of the instructions. Generally it is very difficult for the parallel compiler to know whether the communication is needed or not in advance because variables might be rewritten at any time. Therefore unnecessary communication that users are not aware of frequently happens reducing the efficiency of the parallelization. That is, the compiler just compiles programs considering all cases; it cannot provide a good solution if there exists any uncertain portion, and therefore unexpected and unnecessary communication very often occurs in the execution of a program.
We can succeed in parallelization of the MHD program even in the worst case because the high speed alternation in the directions of decomposition by (4) can solve almost all the difficulties of parallelization in the MHD program, e.g. in the treatment of boundary conditions. We were able to fully parallelize our MHD code by using the function of alternative decomposition when we used Matsusita Electric Co. ADETRAN compiler. We obtained an efficiency of parallelization over 85% using the ADETRAN massively parallel computer with 256 processors. Moreover, we could execute parallel computation in maximum, minimum and summation by using a "reduction" sentence in HPF/JA. Because we had high expectations for translating programs from VPP Fortran to HPF/JA, we soon began to rewrite several test programs as well as the 3-dimensional MHD code.
3. Practical Aspects of Translation From VPP Fortran to HPF/JA
The 3-dimensional global MHD simulation code for the interaction between the solar wind and the earth's magnetosphere solves the MHD and Maxwell's equations in 3-dimensional Cartesian coordinates (x,y,z) as an initial and boundary value problem using a modified leap-frog method [4]. The MHD quantities are decomposed in the z direction as in VPP Fortran. The MHD code, which is fully vectorized and fully parallelized in VPP Fortran, was translated from VPP Fortran to HPF/JA. We summarize below some key points involved in that translation.
To begin with, there is no concept of the global variables in VPP Fortran and also "equivalence" sentence to connect the global variables with local variables cannot be used in HPF/JA. To vectorize for inner do loops and to parallelize for outer do loops is the same in HPF/JA as in VPP Fortran. The efficiency of parallelization increases when the outer do loops are combined in wider range. A part of the 3-dimensional MHD code translated from VPP Fortran to HPF/JA is shown as an example in this section and the MHD code with the complete boundary condition in HPF/JA is seen on a Web page whose address will be shown later in this text. A domain decomposition in the z direction is used and overlap data distributed among PEs are handled by "shadow" and "reflect" in HPF/JA.
Example of our 3-dimensional MHD code translated from VPP Fortran to HPF/JA
parameter (npe=16)
!hpf$ processors pe(npe)
parameter (nx=500,ny=200,nz=400,nxp=150)
parameter (n1=nx+2,n2=n1*(ny+2),n3=n2*(nz+2))
parameter (nb=8,nbb=11,n4=n3*nb,n5=n3*nbb,n6=n3*18)
c
dimension f(nx2,ny2,nz2,nb),u(nx2,ny2,nz2,nb),
1 ff(nx2,ny2,nz2,nb),p(nx2,ny2,nz2,nbb),
2 pp(nx2,ny2,nz2,3),fdd(mfd,nfd)
c
!hpf$ distribute f(*,*,block,*) onto pe
!hpf$ distribute u(*,*,block,*) onto pe
!hpf$ distribute pp(*,*,block,*) onto pe
!hpf$ distribute ff(*,*,block,*) onto pe
!hpf$ distribute p(*,*,block,*) onto pe
!hpf$ shadow f(0,0,1:1,0)
!hpf$ shadow u(0,0,1:1,0)
!hpf$ shadow pp(0,0,1:1,0)
!hpf$ shadow ff(0,0,1:1,0)
!hpf$ shadow p(0,0,1:1,0)
!hpf$ asyncid id1
c
do 100 ii=1,last
c boundary condition at nz=1 and nz=nz2
xx4=0.5*hx*float(2*nxp-nx1-2)
xx3=hhx(nx1)+xx4
c
!hpf$ independent,new(i,j,k,m)
do 31 k=1,nz2
!hpf$ on home(f(:,:,k,:)),local(f,i,j,m,x,xx,xx3,xx4,
!hpf$* hhx) begin
do 30 m=1,nb
if(k.eq.1) then
do 311 j=2,ny1
f(2,j,1,m)=f(1,j,2,m)
do 311 i=3,nx1
x=hhx(i)+xx4
x=1.0-x/xx3
x=amin1(x,1.0)
x=1.0+x/3.0
xx=1.0-x
f(i,j,1,m)=x*f(i-1,j,2,m)+xx*f(i-2,j,3,m)
311 continue
else if(k.eq.nz2) then
do 312 j=2,ny1
f(2,j,nz2,m)=f(1,j,nz1,m)
do 312 i=3,nx1
x=hhx(i)+xx4
x=amin1(x,1.0)
x=1.0+x/3.0
xx=1.0-x
f(i,j,nz2,m)=x*f(i-1,j,nz1,m)+xx*f(i-2,j,nz,m)
312 continue
end if
30 continue
!hpf$ end on
31 continue
c
!hpf$ asynchronous(id1),nobuffer begin
f(2:nx1,1,nz2:1:-1,1:nb) = f(2:nx1,2,1:nz2,1:nb)
!hpf$ end asynchronous
!hpf$ asyncwait(id1)
c
!hpf$ reflect f
c
c first step
c step of k=k
!hpf$ independent,new(i,j,k)
do 90 k=1,nz1
!hpf$ on home(u(:,:,k,:)),local(f,u,p,pp,ff,i,j,m,
!hpf$* x,y,z,hx,hy,hz,xx4,hhx,ar2,
!hpf$* ro2,ro3,dx1,dy1,dz1,gam,eud,gra,ar1,
!hpf$* uxd,x1,x2,x3,x5,y1,y5,ro02,pr02,vmax) begin
c
c current
do 38 j=1,ny1
do 38 i=1,nx1
p(i,j,k,11)=0.25*((f(i+1,j+1,k+1,7)+f(i+1,j,k+1,7)
1 +f(i+1,j+1,k,7)+f(i+1,j,k,7)
2 -f(i,j+1,k+1,7)-f(i,j,k+1,7)-f(i,j+1,k,7)-f(i,j,k,7))/hx
3 -(f(i+1,j+1,k+1,6)-f(i+1,j,k+1,6)+f(i+1,j+1,k,6)-f(i+1,j,k,6)
4 +f(i,j+1,k+1,6)-f(i,j,k+1,6)+f(i,j+1,k,6)-f(i,j,k,6))/hy)
c
!hpf$ end on
90 continue
In the MHD code, all the necessary variables, which appear in the do loop for parallelization, are indicated in the on home(u(:,:,k,:)),local( ) sentence in order to prevent unnecessary communication between PEs (Processing Elements) and to vectorize in the inner do loops. Otherwise, the inner do loops cannot be vectorized. If the inner do loops are not vectorized, we decompose the do loop for parallelization into small do loops and try again to find missing variables in the on home( ), local( ) sentence. It is not difficult to find all the necessary variables in small do loops for parallelization. After the full vectorization is confirmed in each of do loops for parallelization, we combine them to form a wider single do loop for parallelization to obtain higher efficiency. Thus we can accomplish a complete translation of the MHD code from VPP Fortran to HPF/JA.
In VPP Fortran, global and local variables are defined and the two variables are linked by "equivalence" sentence as follows,
c !xocl global gf,gu,gff,gpp,gfdd c equivalence (gf,f),(gff,ff),(gu,u),(gpp,pp)
The local variables are used for all the computation and the corresponding global variables are used only in read and write sentences. However, there is no concept of global variables in HPF and "equivalence" sentence cannot be used. Therefore, we need to prepare a new array for input/output, and lump transmission of distributed data is done for the new array by "asynchronous" sentence. Then we can use the new array for read and write sentences without format, and in doing so retaining a high speed. Of course, the program size increases for the new array. It is noted that lump transmission by "asynchronous" sentence must be used to transfer the distributed data; otherwise it often takes an extremely long time for data transfer. "Asynchronous" sentence has another function to allow lump data transfer of the distributed data with different directions of decomposition.
4. Comparison of Processing Capability using VPP Fortran and HPF/JA
Our aim was to translate the 3-dimensional global MHD code simulating the interaction between the solar wind and the earth's magnetosphere from VPP Fortran to HPF/JA and to achieve an efficiency more than 50% over VPP Fortran [5]-[7]. In the global MHD simulation, the MHD and Maxwell's equations are solved by the modified leap-frog method as an initial value and boundary value problem to study the response of the magnetosphere to variations of the solar wind and the interplanetary magnetic field (IMF) [4],[5]. Because the external boundary is put in a distant region to minimize its influence on the boundary condition and the tail boundary is extended to permit examination of the structure of the distant tail, higher spatial resolution is required to obtain numerically accurate results. Therefore, the number of 3-dimensional grid points was increased up to the maximum limit of the computer system.
Examples of MHD simulations of the solar wind-magnetosphere interaction are shown in Figures 1 and 2 [5],[7]. Figure 1 shows the 3-dimensional structure of magnetic field lines under steady state conditions for the earth's magnetosphere when the IMF is northward and duskward . A dawn-dusk asymmetry appears in the structure of magnetic field lines because magnetic reconnection at the magnetopause occurs in the high latitude tail on the dusk side in the northern hemisphere and on the dawn side in the southern hemisphere. Figure 2 shows a snapshot of the earth's magnetosphere obtained by a 3-dimensional global MHD simulation at a time when the ACE satellite is monitoring the upstream solar wind and IMF every 1 minute. These data were used as input to the simulation. This simulation represents one of the fundamental studies in the international space weather program designed to develop numerical models and to understand the variations in the solar-terrestrial environment from moment to moment. It requires 50-300 hours of computation time to carry out these 3-dimensional global MHD simulations of the earth's magnetosphere for ~25-150 hours of real time data even using 16PEs of the Fujitsu VPP5000/56.
Table 1 shows the comparison of the processing capabilities of VPP Fortran and HPF/JA for the 3-dimensional global MHD code describing the solar wind-magnetosphere interaction run on the Fujitsu VPP5000/56. Both the Fortran codes are fully vectorized and fully parallelized, and are adjusted to reach the maximum performance using the results of several test runs applying practical simulations. The table includes the number of PEs, 3-dimensional grid points (except for the boundary), CPU time (sec) to execute and advance of one time step, computation speed (Gflops) and computation speed per PE (Gflops/PE) for both VPP Fortran and HPF/JA.
The characteristics of the Fujitsu VPP5000/56 in the Computer Center of Nagoya University are as follows,
Number of PEs: 56 PE Theoretical maximum speed of PE: 9.6 Gflops Maximum memory capacity per PE for users: 7.5 GB
As is known from Amdahl's law, it is quite important to fully vectorize for all inner do loops and to fully parallelize for all outer do loops in order to increase the efficiency of the vectorization and parallelization performance. The efficiency would be quite low if even only one do loop could not be vectorized or parallelized. Users can achieve excellent computational performance if they can succeed in vectorizing or parallelizing the last do loop. In the 3-dimensional MHD simulation, the number of grid points is given by nx*ny*nz, decomposition of distributed data is taken in z-direction and the size of the array in z-direction becomes nz2=nz+2. Therefore, it is desirable that the array size in the direction of decomposition, nz2 is chosen to be an integer times the number of PEs. Moreover, the efficiency of vectorization and parallelization becomes better as an number of jobs (viz. the number of grid points nx*ny*nz) increases. The computational results for the scalar mode and for the vector mode with only 1PE are also shown in the Table for the sake of comparison with parallel computation. The meaning of this Table can be easily understood if we look at it from that point of view.
It should be noted from the Table that the vector mode with 1PE is about 40 times faster than the scalar mode and that computational speed of HPF/JA is almost comparable to that of VPP Fortran. Furthermore, the scalability of parallel computation is well satisfied given that the computation speed is roughly proportional to the number of PEs. However, when we look at the Table in more detail, it is noted that it was not suitable to choose the grid number to be nx*ny*nz=500*100*200 as used in the previous simulation for parallel computation. This is because the ratio of the number of array variables in the direction of decomposition (nz2=202=101*2) to the number of PEs is not normally an integer. This follows from the fact that the computation speed increases, but is lower than the speed expected from linear proportionality to the number of PEs.
The scalability is greatly improved when we choose the number of grid points as nx*ny*nz=200*100*478 (nz2=480=2**5*3*5) and 800*200*670 (nz2=672=2**5*3*7) in the MHD simulation. Furthermore we achieved a rather high performance exceeding 400 Gflops in both cases of VPP Fortran and HPF/JA when we chose a large number of grid points given by nx*ny*nz=1000*500*1118 and 1000*1000*1118. This is because nz2 is an integer times the number of PEs and also the program size of MHD code became larger. These results clearly show that a 3-dimensional global MHD simulation of the earth's magnetosphere can be performed at a speed of over 400 Gflops with an efficiency of 76.5% using 56 PEs of Fujitsu VPP5000/56 in vector and parallel computation that permitted comparison with catalog values.
Concrete examples of the MHD codes translated from VPP Fortran to HPF/JA are not shown in the present paper, however a part of the boundary condition in the HPF/JA MHD code and a test program of the 3-dimensional wave equation can been seen on a Web page which will be shown later.
Some important and general points in using the HPF/JA in Fujitsu VPP5000 are as follows:
The first point refers to the local sentence. If all the parameters are removed in local sentence of "on home local( )", it is equivalent to arranging all the variables and array from "begin" to "end on" to be completely written in the local sentence. Therefore it is convenient to use the function in the "do loop" sentence for the fully vectorized and fully parallelized "do loop" in the VPP Fortran program.
The second point refers to read and write sentences. If distributed array data are not very numerous, it is convenient to use unformatted read and write sentences such as
write(*,100) a,b,c
write(10) a,b,c
which is simple description and for which the execution time is not long. Moreover, we can also use the following unformatted read and write sentences for a part of large array of distributed data without arranging a new array.
do 174 m=1,nb
do 174 k=1,nz2
read(10) f(1:nx2,1:ny2,k,m)
174 continue
do 176 m=1,nb
do 176 k=1,nz2
write(ntap) f(1:nx2,1:ny2,k,m)
176 continue
This method does not require any increase of the program size in input and output for a large array of distributed data and the execution time is almost comparable to that a newly arranged array is prepared to use a copy function by asynchronous sentence. Therefore, we can keep the program size of HPF/JA, where "equivalence" sentence cannot be used to link global and local variables, the same as for VPP Fortran.
5. Development of MHD Simulation
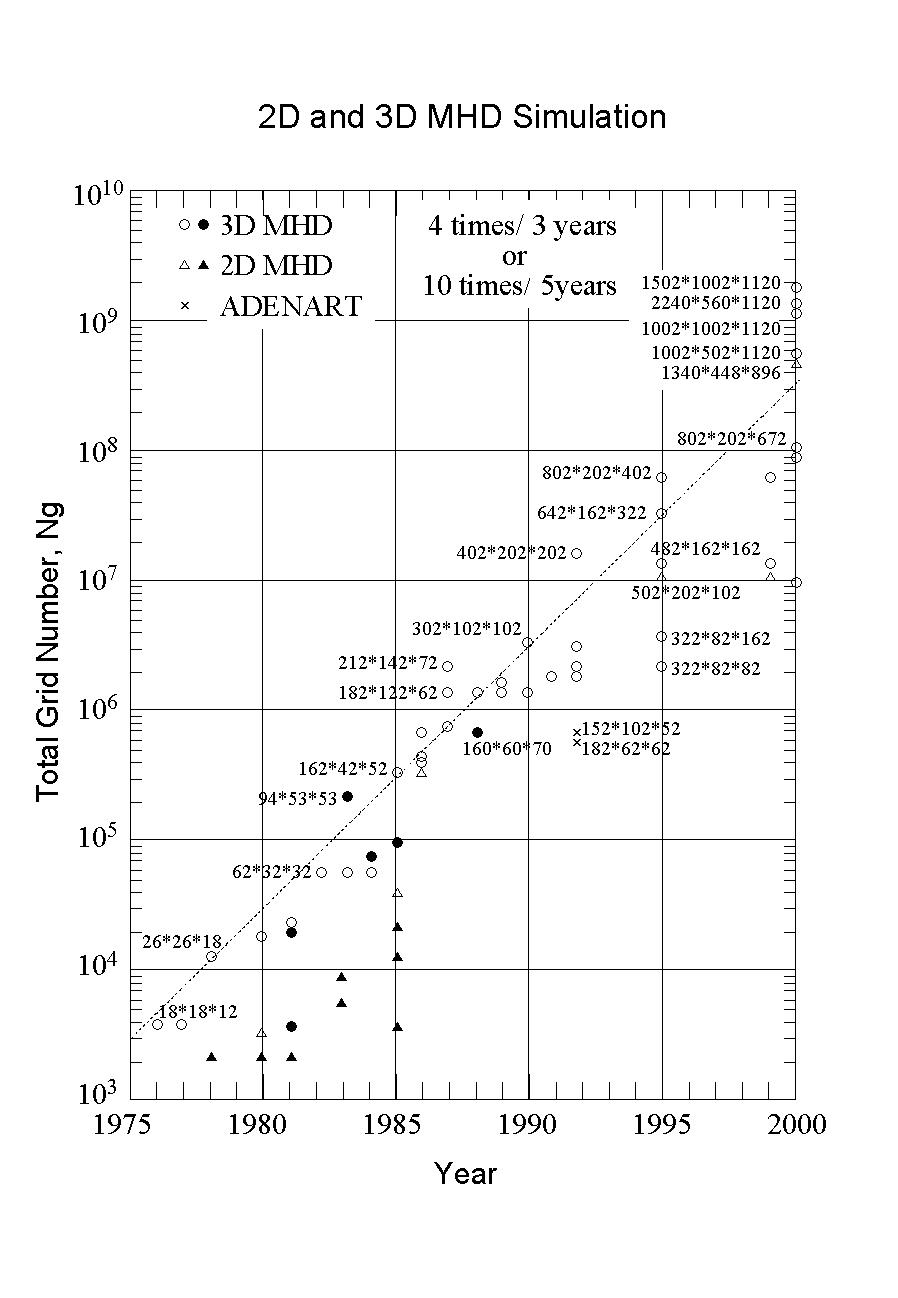
Since 2 and 3-dimensional global MHD simulations of the interaction between the solar wind and the earth's magnetosphere have been carried out over the past 20 years [1]-[6],[13],[14], it is useful to present a short history of their development and evaluate their future. Figure 3 shows a summary plot of the 2 and 3-dimensional global MHD simulations indicating how many grid points were used as the years went by. In this figure, the black circles and triangles show the MHD simulations carried out by other groups, while the white ones and crosses show the MHD simulations carried out by our group. We began the 3-dimensional MHD simulations to study MHD instabilities in toroidal plasmas using small number of grid points (given by 18*18*12 and 26*26*18 including the boundary) in 1976 [13],[14]. However, the MHD simulations required about 50-200 hours of computing time using Fujitsu M-100 and M-200 computers. The execution of such large scale MHD simulations was practically limited by speed of the computers at that time.
We began a global MHD simulation of the earth's magnetosphere using a larger number of grid points (given by 62*32*32 and 50*50*26, including the boundary) using a CRAY-1 in 1982 [1]-[3], when the memory of CRAY-1 of 1MW limited the scale of the MHD simulation. At that time, we considered how many interesting simulations could be executed if 100 cube grid points could be used. The Japanese supercomputers subsequently appeared, and we could carry out the MHD simulations with 100 cube grid points using Fujitsu VP-100, VP-200 and VP-2600 machines. Later, we had an opportunity to use the Fujitsu VPP500 vector parallel machine in 1995 and began to use the VPP5000 machine in 2000; this practically allowed us to carry out the MHD simulation with 1000 cube grid points. When we look at the development of the MHD simulations from the point of view of the number of grid points used over those 24 years, we can recognize the pattern of a 4 fold increase every 3 years or a 10 fold increase every 5 years.
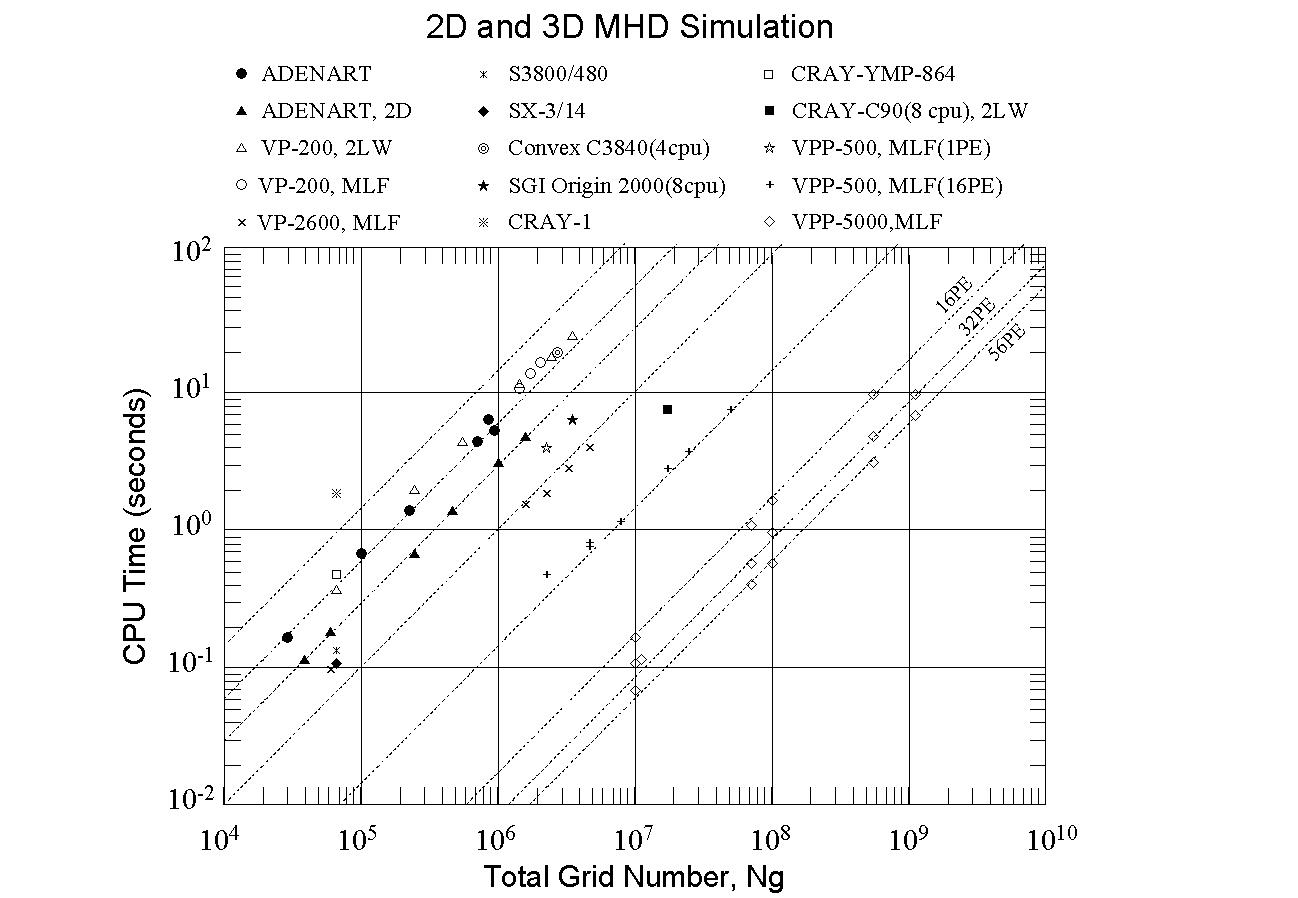
Figure 4 shows the computation time for an advance of one time step which is needed to execute the MHD simulation, while Figure 5 shows the capacity of the computer memory which is needed to execute the MHD simulation along with the total number of grid points. The computation time and capacity generally depend of the kind of computer and numerical methods, and the computation time becomes longer and the required computer memory increases in linear proportion to the number of total grid points. Since the global MHD simulation of the earth's magnetosphere requires repetitive calculations from several thousand to tens of thousands times the one time step advance, it is necessary to make the computation time of one time step advance less than 10 seconds in order to carry out practical MHD simulations [5],[6],[8]. Thus, the number of usable grid points is automatically limited in MHD simulations by the speed of the computer. At the same time, the program size for MHD simulations with the chosen number of grid points must be less than size of the computer memory.
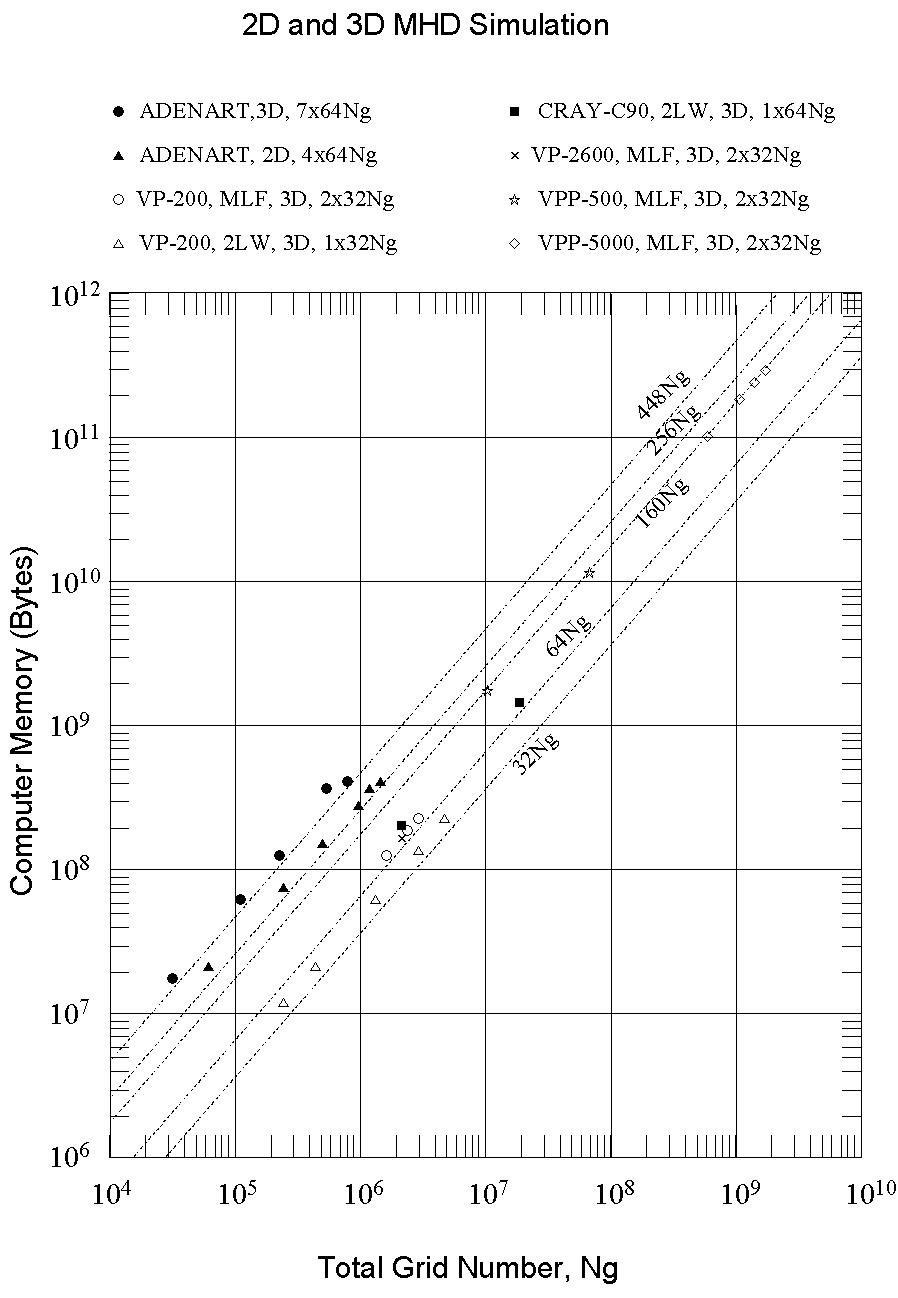
Since the time evolution of 8 physical components (i.e. the density, 3 components of velocity, plasma pressure and 3 components of magnetic field) is calculated in the MHD code, the number of independent variables is 8 Ng and the capacity is 32 Ng Bytes in single precision variables, where Ng is the total number of grid points. Therefore, the key variables in the MHD code are 32 Ng Bytes using the 2 step Lax-Wendroff method (2LW) and 64 Ng Bytes using the modified Leap-Frog method (MLF) because the MHD quantities must be stored for two consecutive time steps. The 3-dimensional global MHD code which was originally developed for the CRAY-1 and has been used by other vector machines requires only 1.3 times the capacity to store the MHD key variables for a 1-dimensional array in order to effectively decrease the work area. It becomes impossible to effectively decrease the work area for parallel computers, as a result the program size increases considerably in parallel machines such as ADENART, VPP500 and VPP5000.
However, the required memory in VPP500 and VPP5000 is 2.5 times the available memory of the computer to store the key variables (160 Ng=2.5*64 Ng) in MLF. If the dependence on required memory for the total grid number could be concretely demonstrated, we could easily estimate how large an MHD simulation could be executed to study specified subjects and could establish more precisely the prospects for the future.
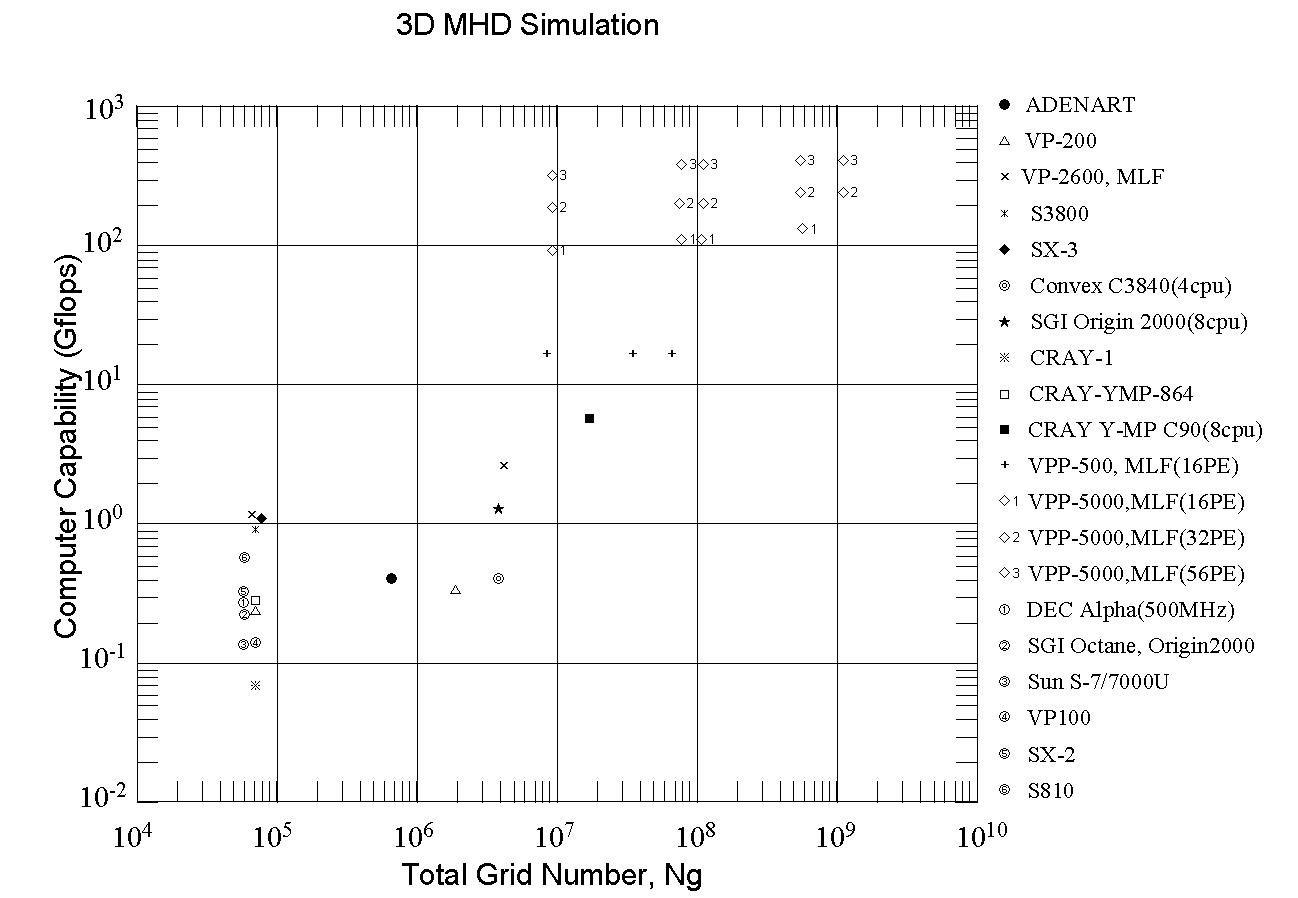
Figure 6 shows a comparison of the computer processing capability with the total grid number in MHD simulations. Rapid progress has been made in increasing performance by moving from vector machines to vector parallel machines. Newer high performance workstations and personal computers have the capability of older supercomputers (speed of about 0.3 Gflops). However, the processing capability of high end supercomputers is still about a thousand times higher than that of other computers at all times. Moreover, definitive differences between supercomputers and other computers appear in the shortage of main memory and cache required to carry out MHD simulations with a large number of grid points. It is practically impossible to execute a 3-dimensional MHD simulation code using workstations and personal computers when the fully vectorized and fully parallelized MHD code would need CPU times of 100 hours using a supercomputer such as the Fujitsu VPP5000. It is nowadays necessary to use a supercomputer with a maximum performance capability in studies involving 3-dimensional global MHD simulations of the earth's magnetosphere.
6. Conclusions
We have carried out a 3-dimensional global magnetohydrodynamic (MHD) simulation of the interaction between the solar wind and the earth's magnetosphere on a variety of computers using a fully vectorized MHD code. However, simulation scientists have lost their common language with the appearance of vector parallel and massive parallel supercomputers. We sincerely hope to see the development of a common language in the supercomputer world. The candidates appear to be High Performance Fortran (HPF) and Message Passing Interface (MPI). We look forward to the time when we can use these compilers in supercomputers.
We have had the opportunity to use HPF/JA with the Fujitsu VPP5000/56 supercomputer in the Computer Center of Nagoya University since June 2000. We translated our 3-dimensional MHD simulation code for the solar-terrestrial interaction from VPP Fortran to HPF/JA and the code was fully vectorized and fully parallelized in VPP Fortran. The performance of the HPF MHD code was almost comparable to that of the VPP Fortran in a typical simulation using a large number (56) of Processing Elements (PEs). We have reached the conclusion that fluid and MHD codes that are fully vectorized and fully parallelized in VPP Fortran can be relatively easily translated to HPF/JA, and a code in HPF/JA can be expected to achieve comparable performanceto one written in VPP Fortran.
The 3-dimensional global MHD simulation code for the earth's magnetosphere solves the MHD and Maxwell's equations in 3-dimensional Cartesian coordinates (x, y, z) as an initial and boundary value problem using a modified leap-frog method. The MHD quantities are distributed in the z direction. The quantities in the neighboring grids can be calculated by the HPF/JA instruction sentences "shadow" and "reflect" when they exist in another PE. Unnecessary communication among PEs can be completely avoided by the instructions "independent, new," and "on home, local." Moreover, lump transmission of data is used in the calculation of the boundary conditions by the instruction "asynchronous." It was not necessary to change the fundamental structure of the MHD code in the translation procedure. This was a big advantage in translating the MHD code from VPP Fortran to HPF/JA.
Based on this experience, it is anticipated that we will find little difficulty in translating programs from VPP Fortran to HPF/JA, and we can expect an almost comparable performance on the Fujitsu VPP5000. The maximum speed of the 3-dimensional MHD code was over 230 Gflops for 32 PEs and over 400 Gflops for 56 PEs. We hope that the MHD code rewritten in HPF/JA can be executed on other supercomputers such as the Hitachi SR8000 and the NEC SX-5 in near future and that HPF/JA becomes a useful common language in the supercomputer world. We believe that this is a necessary condition to restart a new and higher level of collaborative research on 3-dimensional global MHD simulation of the magnetosphere with other scientists around the world and expect to see efforts by simulation scientists as well as by the Japanese supercomputer companies to reach this goal.
We have made available a part of the boundary condition in the HPF/JA MHD code and a test program of the 3-dimensional wave equation at the following Web address:
http://gedas.stelab.nagoya-u.ac.jp/simulation/hpfja/hpf01.html.
Acknowledgments.
We would like to thank the staff of the Computer Center of Nagoya University and the SEs of the Fujitsu company for their helpful discussions and support. We thank G. Rostoker for useful comments. This work was supported by a grant in aid for science research from the Ministry of Education, Science and Culture. Computing support was provided by the Computer Center of Nagoya University.
References
[1] Ogino T., R.J. Walker, M. Abdalla and J.M. Dawson, An MHD simulation of
By-dependent magnetospheric convection and field-aligned currents during
northward IMF, J. Geophys. Res. 90, 10835-10842, 1985.
[2] Ogino T., A three-dimensional MHD simulation of the interaction of the
solar wind with the earth's magnetosphere: The generation of
field-aligned currents, J. Geophys. Res., 91, 6791-6806, 1986.
[3] Ogino T., R.J. Walker, M. Abdalla and J.M. Dawson, An MHD simulation of
the effects of the interplanetary magnetic field By component on the
interaction of the solar wind with the earth's magnetosphere during
southward interplanetary magnetic field, J. Geophys. Res., 91,
10029-10045, 1986.
[4] Ogino T., R.J. Walker and M. Ashour-Abdalla, A global magnetohydrodynamic
simulation of the magnetosheath and magnetopause when the interplanetary
magnetic field is northward, IEEE Transactions on Plasma Science,
Vol.20, No.6, 817-828, 1992.
[5] Ogino T., R.J. Walker and M. Ashour-Abdalla, A global magnetohydrodynamic
simulation of the response of the magnetosphere to a northward turning of
the interplanetary magnetic field, J. Geophys. Res., Vol.99, No.A6,
11,027-11,042, 1994.
[6] Ogino, T., R.J. Walker, and M.G. Kilvelson, A global magnetohydrodynamic
simulation of the Jovian magnetosphere, J. Geophys. Res., 103,
225-235, 1998.
[7] Ogino, T., Magnetohydrodynamic simulation of interaction between the
solar wind and magnetosphere, J. Plasma and Fusion Research,
(Review paper), Vol.75, No.5, CD-ROM 20-30, 1999.
[8] Ogino, T., Computer simulation of solar wind-magnetosphere interaction,
Center News, Computer Center of Nagoya University, Vol.28, No.4,
280-291, 1997.
[9] Fujitsu Co., VPP Fortran Programming, UXP/V, UXP/M Ver.1.2, April, 1997.
[10] Tsuda, T., On usage of supercomputer VPP5000/56,
Center News, Computer Center of Nagoya University, Vol.31, No.1,
18-33, 2000.
[11] High Performance Fortran Forum, Official Manual of High Performance
Fortran 2.0, Springer, 1999.
[12] Fujitsu Co., HPF programming -parallel programming (HPF version)-,
UXP/V Ver.1.0, June, 2000.
[13] Ogino T., H. Sanuki, T. Kamimura and S. Takeda, Nonlinear evolution of
the resistive MHD modes in a toroidal plasma, J. Phys. Soc. Japan,
50, 315-323, 1981.
[14] Ogino T., H. Sanuki, T. Kamimura and S. Takeda, Nonlinear evolution of
the kink ballooning mode in a toroidal plasma, J. Phys. Soc. Japan,
50, 1698-1705, 1981.
Table 1. Comparison of processing capabilities of VPP Fortran and HPF/JA in a 3-dimensional global MHD code for the solar wind-magnetosphere interaction using a Fujitsu VPP5000/56.
Number Number of VPP Fortran HPF/JA
of PE grids cpu time Gflops Gf/PE cpu time Gflops Gf/PE
1PE 200x100x478 119.607 ( 0.17) 0.17 (scalar)
1PE 200x100x478 2.967 ( 6.88) 6.88 3.002 ( 6.80) 6.80
2PE 200x100x478 1.458 ( 14.01) 7.00 1.535 ( 13.30) 6.65
4PE 200x100x478 0.721 ( 28.32) 7.08 0.761 ( 26.85) 6.71
8PE 200x100x478 0.365 ( 55.89) 6.99 0.386 ( 52.92) 6.62
16PE 200x100x478 0.205 ( 99.38) 6.21 0.219 ( 93.39) 5.84
32PE 200x100x478 0.107 (191.23) 5.98 0.110 (186.13) 5.82
48PE 200x100x478 0.069 (297.96) 6.21 0.074 (276.96) 5.77
56PE 200x100x478 0.064 (319.53) 5.71 0.068 (299.27) 5.34
1PE 500x100x200 2.691 ( 7.94) 7.94 2.691 ( 7.94) 7.94
2PE 500x100x200 1.381 ( 15.47) 7.73 1.390 ( 15.37) 7.68
4PE 500x100x200 0.715 ( 29.97) 7.47 0.712 ( 29.99) 7.50
8PE 500x100x200 0.398 ( 53.65) 6.71 0.393 ( 54.38) 6.80
16PE 500x100x200 0.210 (101.87) 6.37 0.202 (105.74) 6.61
32PE 500x100x200 0.131 (163.55) 5.11 0.120 (175.50) 5.48
48PE 500x100x200 0.100 (214.48) 4.46 0.091 (231.69) 4.82
56PE 500x100x200 0.089 (239.48) 4.28 0.086 (244.85) 4.37
4PE 800x200x670 7.618 ( 30.06) 7.52 8.001 ( 28.62) 7.16
8PE 800x200x670 3.794 ( 60.36) 7.54 3.962 ( 57.81) 7.23
12PE 800x200x670 2.806 ( 81.61) 6.80 3.005 ( 76.21) 6.35
16PE 800x200x670 1.924 (119.00) 7.44 2.012 (113.85) 7.12
24PE 800x200x670 1.308 (175.10) 7.30 1.360 (168.44) 7.02
32PE 800x200x670 0.979 (233.85) 7.31 1.032 (221.88) 6.93
48PE 800x200x670 0.682 (335.62) 6.99 0.721 (317.80) 6.62
56PE 800x200x670 0.595 (384.61) 6.87 0.628 (364.87) 6.52
16PE 1000x500x1118 9.668 (123.52) 7.72 9.619 (125.50) 7.84
32PE 1000x500x1118 5.044 (236.73) 7.40 4.992 (241.83) 7.56
48PE 1000x500x1118 3.550 (336.40) 7.01 3.479 (346.97) 7.23
56PE 1000x500x1118 2.985 (400.04) 7.14 2.935 (411.36) 7.35
32PE 1000x1000x1118 9.979 (239.33) 7.48 9.813 (243.37) 7.61
48PE 1000x1000x1118 7.177 (332.79) 6.93 7.028 (339.85) 7.08
56PE 1000x1000x1118 5.817 (410.55) 7.33 5.794 (412.23) 7.36
------------------------------------------------------------------------
: Gflops is an estimated value for comparison with a computation by
1 processor of a CRAY Y-MP C90
Figure Captions
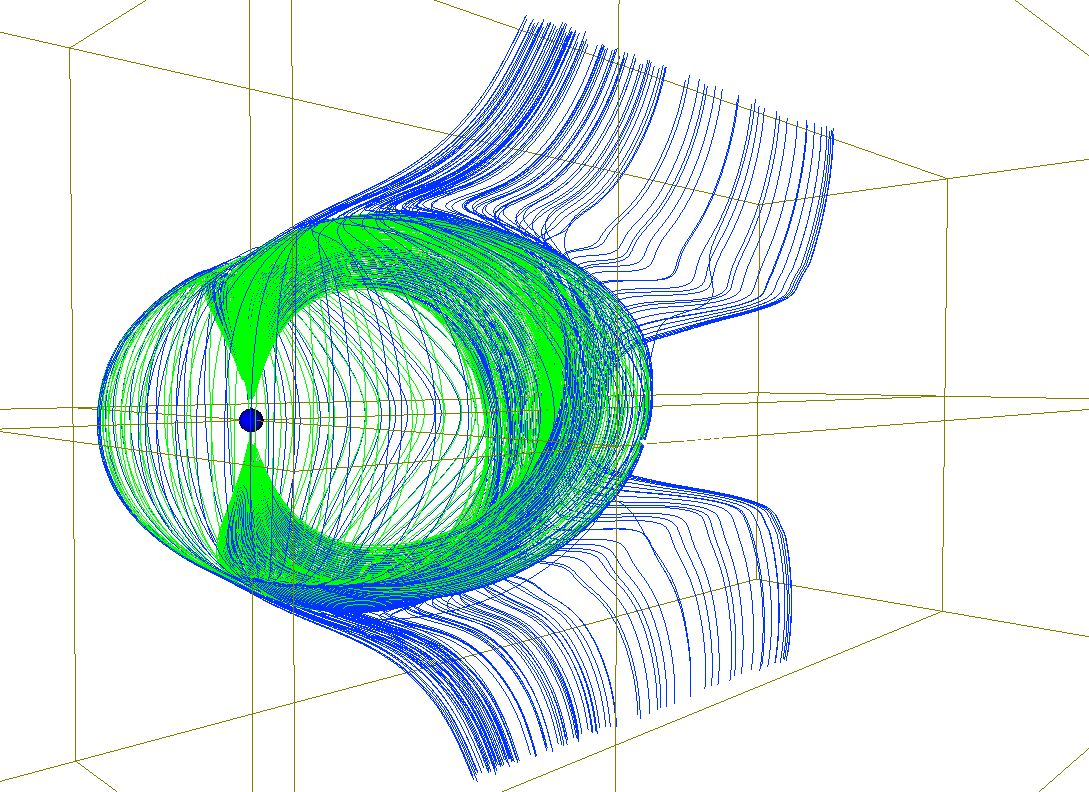
Figure 1 Structure of 3-dimensional magnetic field lines for steady state conditions in the earth's magnetosphere and an interplanetary magnetic field which is northward and duskward. An asymmetry appears in the magnetosphere due to the occurrence of magnetic reconnection on the dusk side in the northern hemisphere and on the dawn side in the southern hemisphere near the magnetopause.
Figure 2 Examples of snapshots of the earth's magnetosphere obtained by 3-dimensional global MHD simulation, when the observational data of the solar wind and interplanetary magnetic field obtained by the ACE satellite were used as input for the simulation.
Figure 3 Development of 2 and 3-dimensional MHD simulations as quantified by the total number of grid points used; the total number of grid points has increased 4 fold every 3 years or 10 fold every 5 years.
Figure 4 Comparison of computation times corresponding to an advance of one time step versus total number of grid points in the MHD simulation codes.
Figure 5 Comparison of total capacity of the necessary memory versus total number of grid points in the MHD simulation codes.
Figure 6 Comparison of the processing capability versus total number of grid points in the MHD simulation codes.
 STELab Home Page.
STELab Home Page.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}